Tutorial: Kafka Ingestion
To get comfortable with Druid and Streaming from Apache Kafka, we'll walk you through loading a sample data set. If you have yet configured an Apache Kafka instance that is accessible by RillData, please see the documentation on Connecting Sources for Kafka.
Tutorial: Load an Apache Kafka Topic into Apache Druid
This tutorial goes through building the specification through the UI. If you have multiple similar specifications to create, it is recommended going to Edit Spec and copying/pasting that spec and then start the UI process. This will save a lot of redo/boiler-plate setup that you have already established from previous ingestions.
Click on
Druid ConsoleThis is a button in the upper right of RCC. A new tab will be created for you that displays the Druid console. You'll see see
Load Data,Ingestion, andQuerytabs.Click on the
Load DataIf you've loaded data recently, you will see two buttons that give you the choice of "Start a new spec" or "Continue from previous spec". If you see these buttons, click Start a new spec.
Select "Apache Kafka" and then Click on Connect data ->.
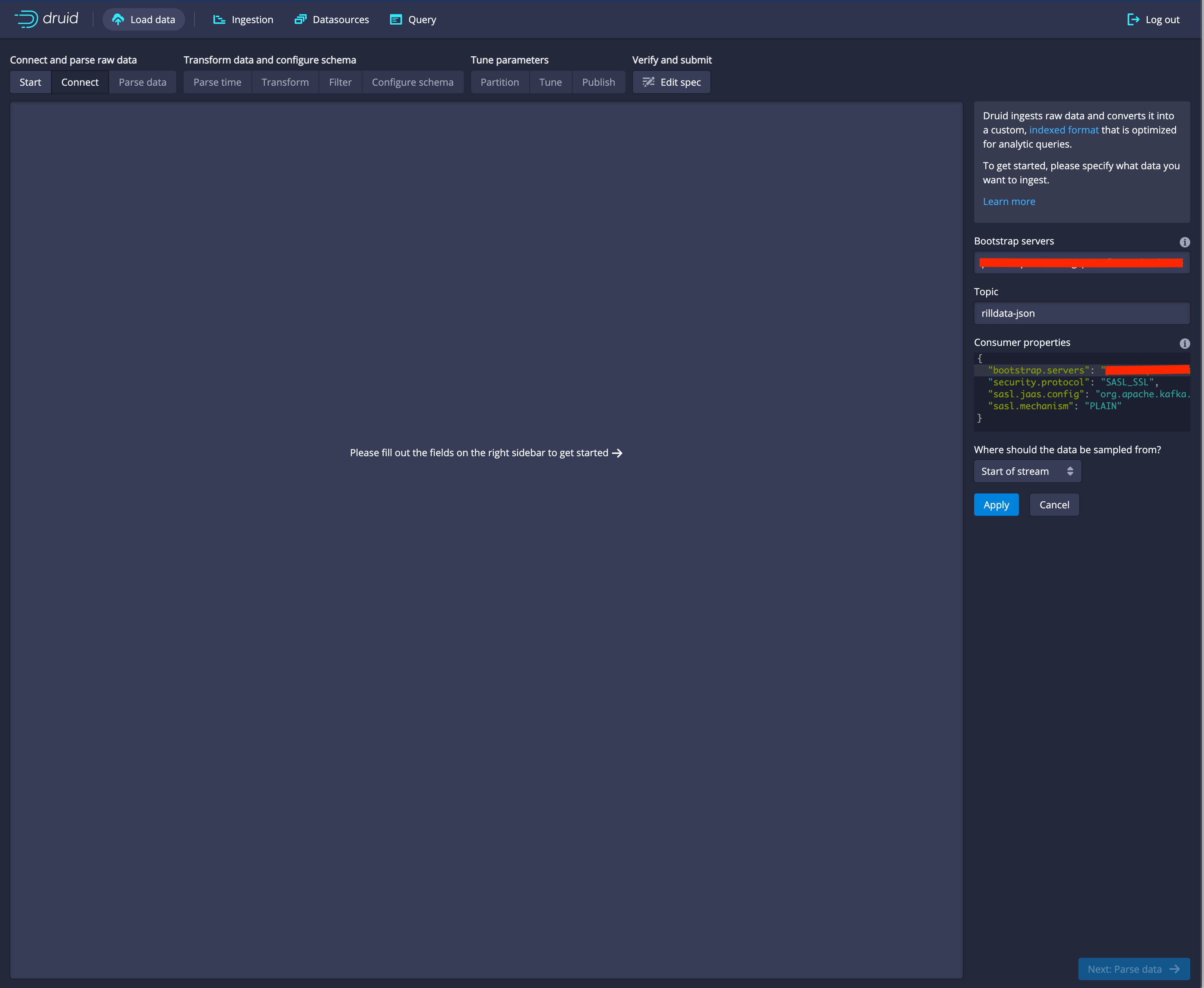
Using the bootstrap server, topic, and credentials from your Apache Kafka Cluster, enter them here. For Confluent Cloud, the bootstrap server will be provided from the Cluster dashboard. Credentials should be obtained through the API tools also provided. See the Connecting Sources for Kafka for additional details on establishing connection information.
| Property | Description | Example |
|---|---|---|
| Bootstrap server | foo.us-east4.gcp.confluent.cloud:9092 | |
| Topic | the topic to stream into RillData | rilldata-json-example |
| Consumer properties | The bootstrap server will be copied from above, but all other Kafka consumer properties that are needed to consume, should be added. At a minimum the security information. | { "bootstrap.server": "foo.us-east4.gcp.confluent.cloud:9092", "security.protocol" : "SASL_SSL", "sasl.jaas.config" : "org.apache.kafka.common.security.plain.PlainLoginModule required username='{{KEY}}' password='{{SECRET}}';", "sasl.mechanism": "PLAIN"} |
| Where should the data be sampled from | read from earliest offset in the topic or start with what is currently being written. | Start of stream |
This loads the example data and displays your data, giving you a chance to verify that the data is being parsed as you expect. In this example we are looking at OpenSky Network data which was populated to a Kafka topic using an open-source Kafka connector for the OpenSky Network data.
The tabs along the top of the page:
Start,Connect,Parse data, ...Publishrepresent stages in the ingestion process. In this example you will move from stage to stage by clicking theNextbutton in the bottom right of the page. Each time you click theNextbutton, Druid will move to the next stage, making its best guess as to the appropriate parameters.The highlighted tab at the top will indicate the stage you have just moved to and if you want to re-execute that stage with different parameters, you can change the parameters in the form at the right and then clickApply.In the next steps you will walk through these stages of the ingestion process by clicking the button in the bottom right (currently
Next: Parse date), but you can also move back and forth among the steps by clicking on the tabs at the top.Click on
Next: Parse dataThe data loader parses the data based on its best guess about the type and displays a data preview. In this case the data is json and it chooses json, as shown by the
input formatfield.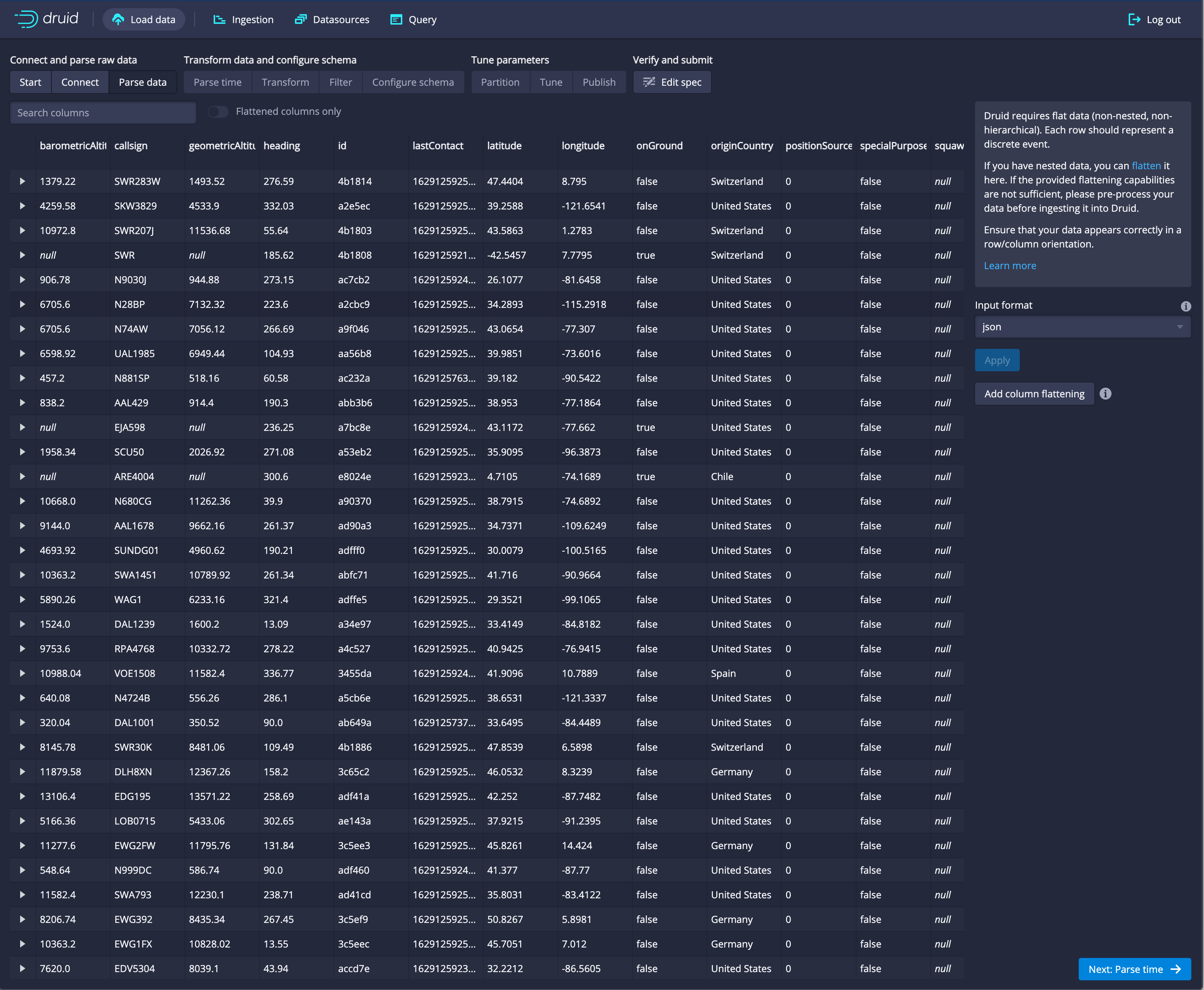
If the data was not json, you could change this and click apply. Click on the
input formatfield to get a sense of the other choices, and feel free to click apply, but make sure JSON is selected and the display shows your data before you proceed to the next step.Click
Next: Parse timeThis step analyzes the data to identify a time column, and moves that column to the far left, with the column name __time. You can see that it is coming from the column originally labeled 'time'.
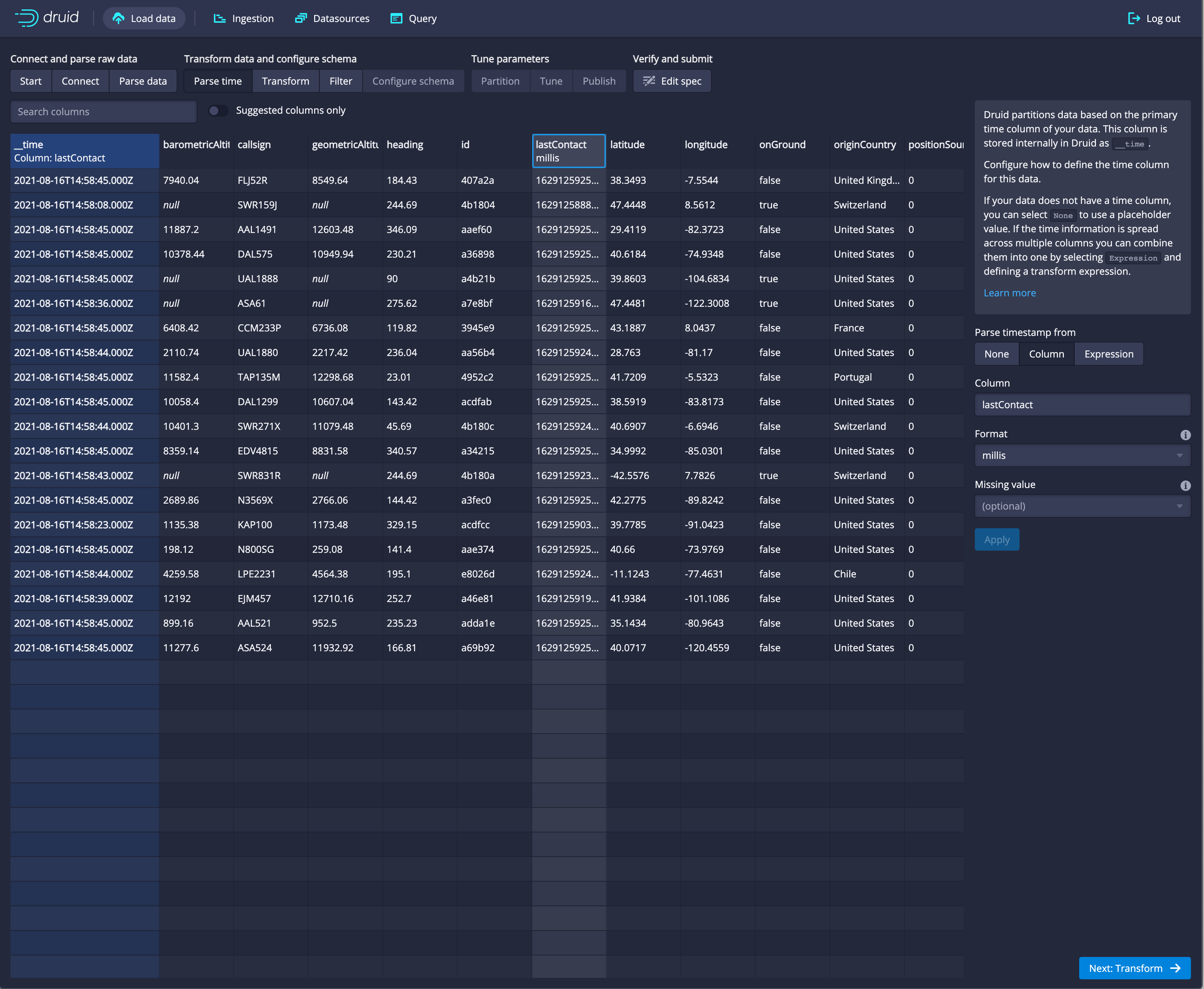
In this example there are 2 columns with time data, one is when the time was pulled from open-sky, and one is when open-sky obtained the information. When multiple choices are provided, you need to pick what makes sense to your business use-case for this dataset.
Druid does not have the means to use the event time associated with the record, if you need to leverage the event time, that will need to be added to the content of the message on the topic.
Druid requires that you specify a timestamp column and does optimizations based on this column. If your data does not have a timestamp column, you can select Constant value, or if your data has multiple timestamp columns, this is your opportunity to select a different one. If you specify a different time column than the default, you click Apply to apply your new setting.
In this example, the data loader determines that the time column is the only candidate to be used as a time column. That's our only time column in this data set, so we leave it set as is.
Click
Next: TransformIn this step we have the opportunity to transform one or more columns or add new columns. See the Data Ingestion Tutorial for an example transformation.
There is a rich SQL set of functions available, see https://druid.apache.org/docs/0.21.0/misc/math-expr.html.
Click on
Next: FilterHere you have the opportunity to filter out rows. To see the syntax, click on
filterlink in the help, which will take you to https://druid.apache.org/docs/0.21.0/querying/filters.html.Click on
Next: Configure Schema.This takes you to a stage where you have the ability to do all of the following:
+ specify what dimensions and metrics are included in your dataset
+ aggregate measures to a coarser level of detail
+ create new measures that represent aggregations based on Sketches or HLL. For example you can create a measure that represents an approximation of a count or a unique count of a dimension.Druid will make assumptions based on the data-types, use this to correct those datatypes. For example, velocity, altitude, latitude, and longitude are not topically metrics so we will convert them from metrics back to dimensions of type double.
Select a column and then use the information to adjust.
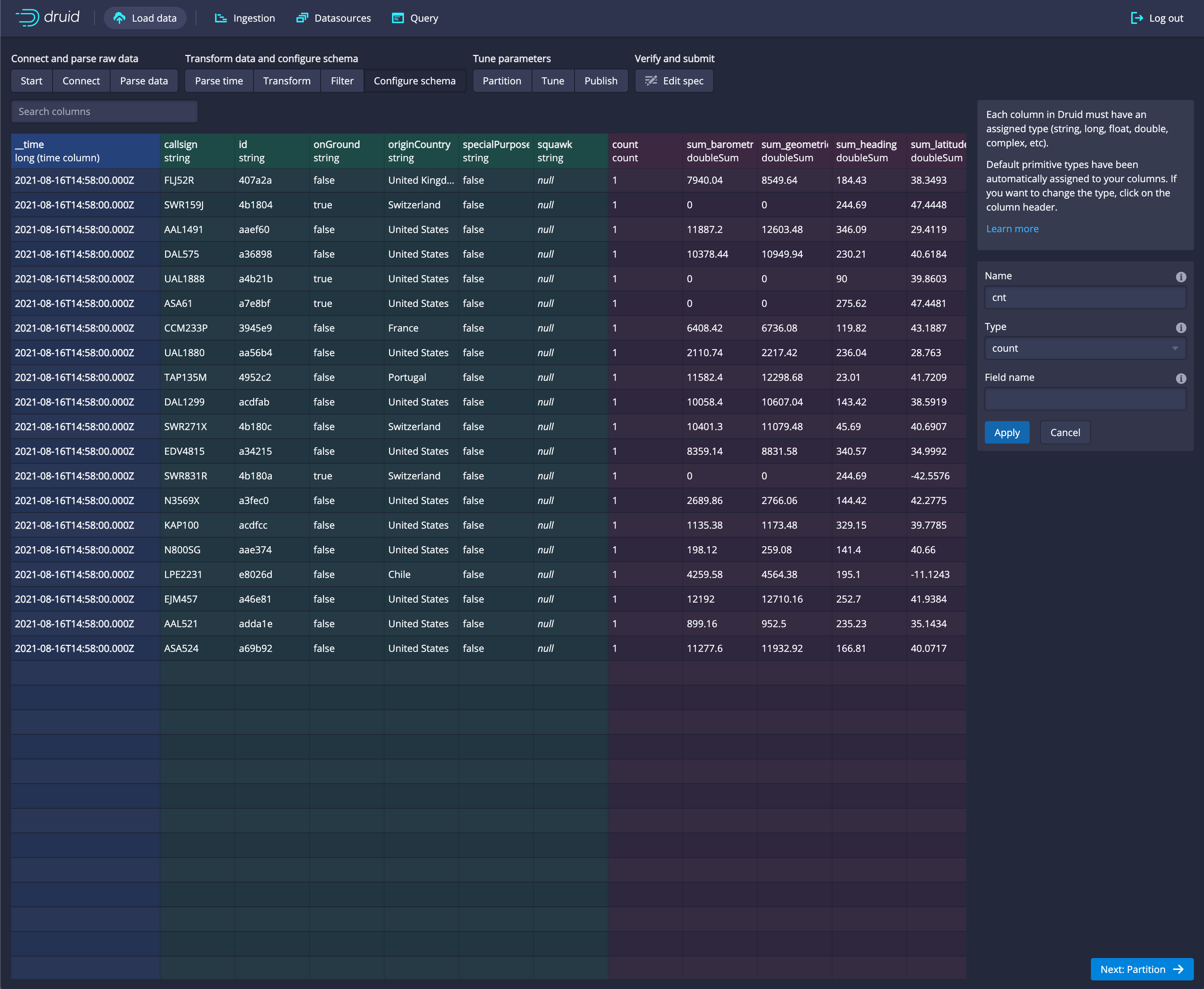
Click
Next: PartitionHere in the partition panel you can choose an optimal way to segment your data across the druid cluster. You'll be segmenting based on your time dimension and you can segment at the same granularity as your time aggregation or a coarser granularity. For example, if you've chosen to aggregate (rollup/query granularity) your data to the hour, you can choose to physically segment it by hour, by day, by week or by month. For now leave it set to the default,
Hour'.
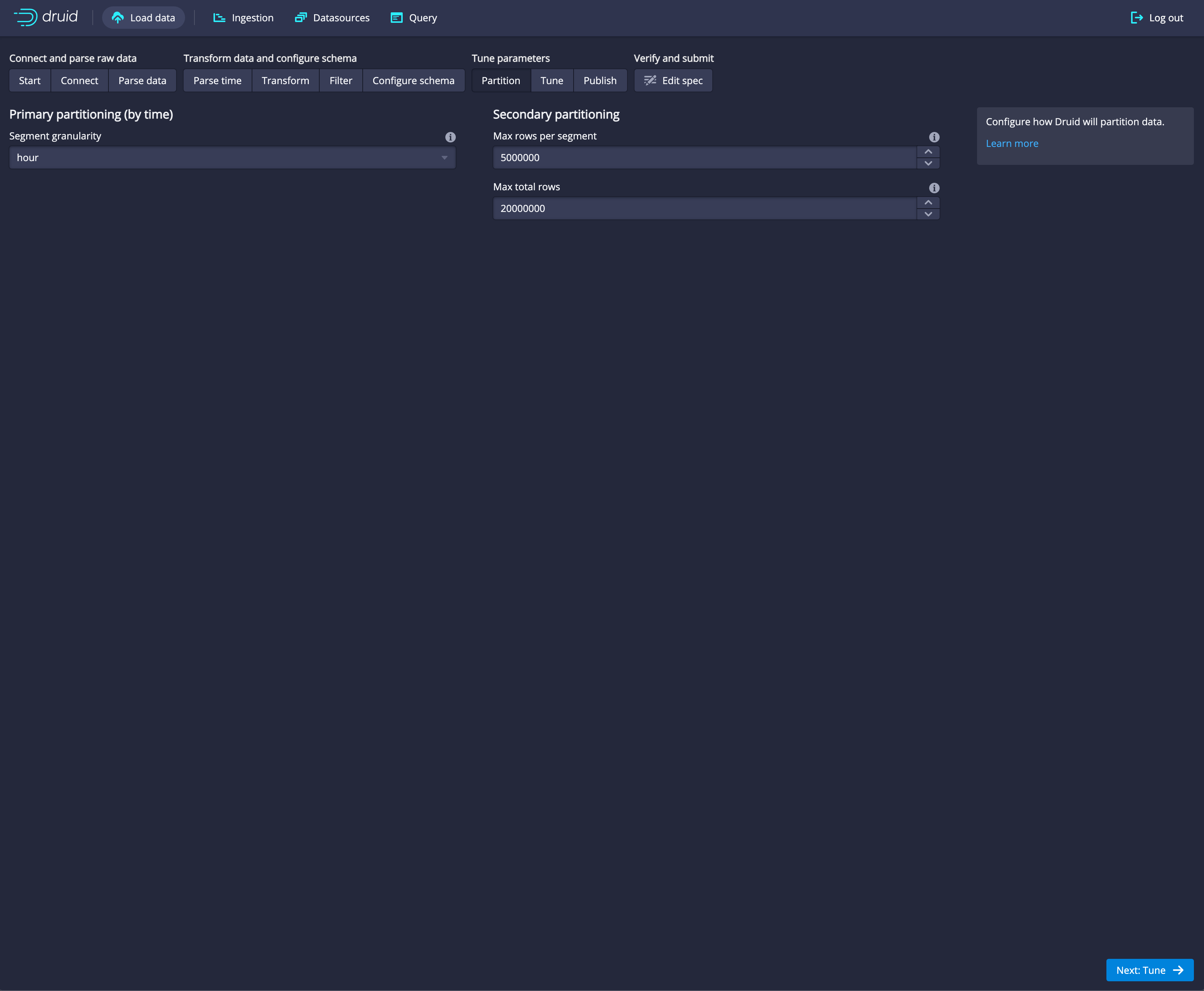
Click
Next: tuneThis allows you to tune the ingestion.
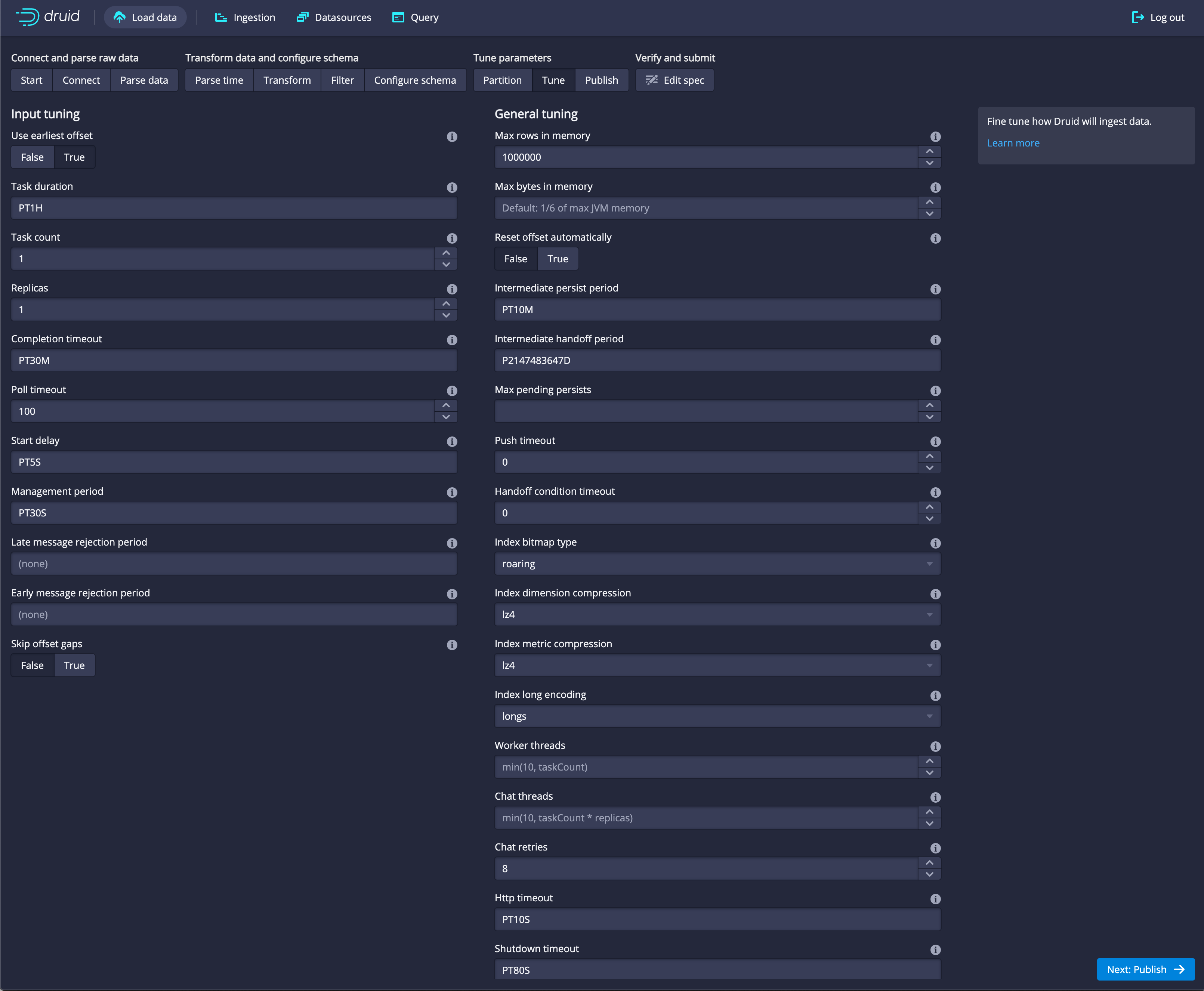
Click
Next: publishHere you can choose the name of your new dataset by filling in the
Datasource namefield.
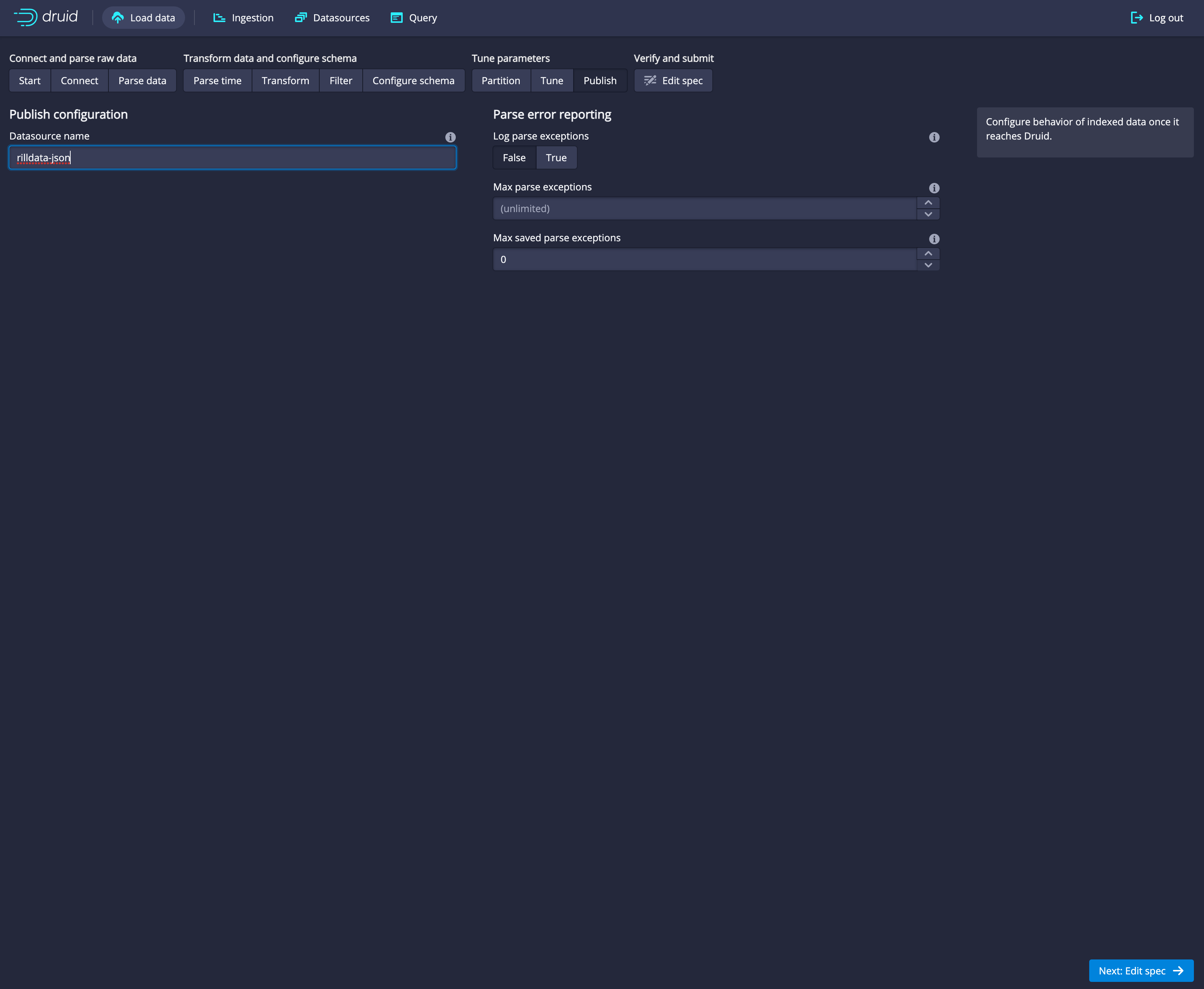
Click
Next: Edit SpecThe json representation of the spec that you just created is displayed. You could edit this by hand (and you can also generate this by hand). Right now we want to go ahead and create our dataset based on the ingestion spec as is, so we won't make any changes.
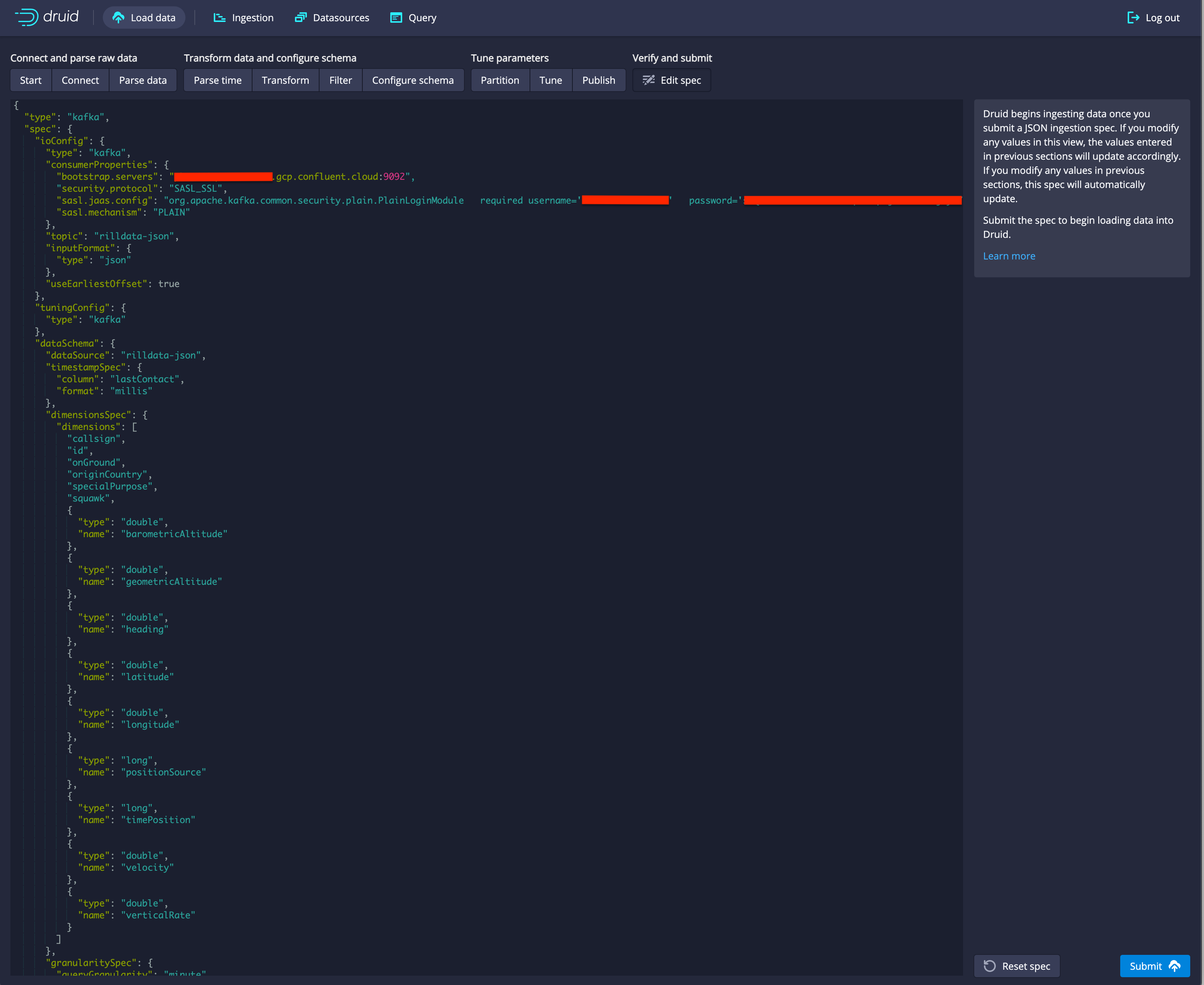
Click
SubmitYou are taken to a panel that shows that status of your job. It will first show the job as running, and then when it's done, the "Running" string will change to "Success". Once it shows success, you can query your data.

Click
Query(rightmost tab at the top)This takes you to the Druid SQL console where you can use SQL to query your data. For example
SELECT
__time,
barometricAltitude,
callsign,
"count",
geometricAltitude,
heading,
id,
latitude,
longitude,
onGround,
originCountry,
positionSource,
specialPurpose,
timePosition,
velocity,
verticalRate
FROM "rilldata-json"
WHERE __time >= CURRENT_TIMESTAMP - INTERVAL '1' DAY
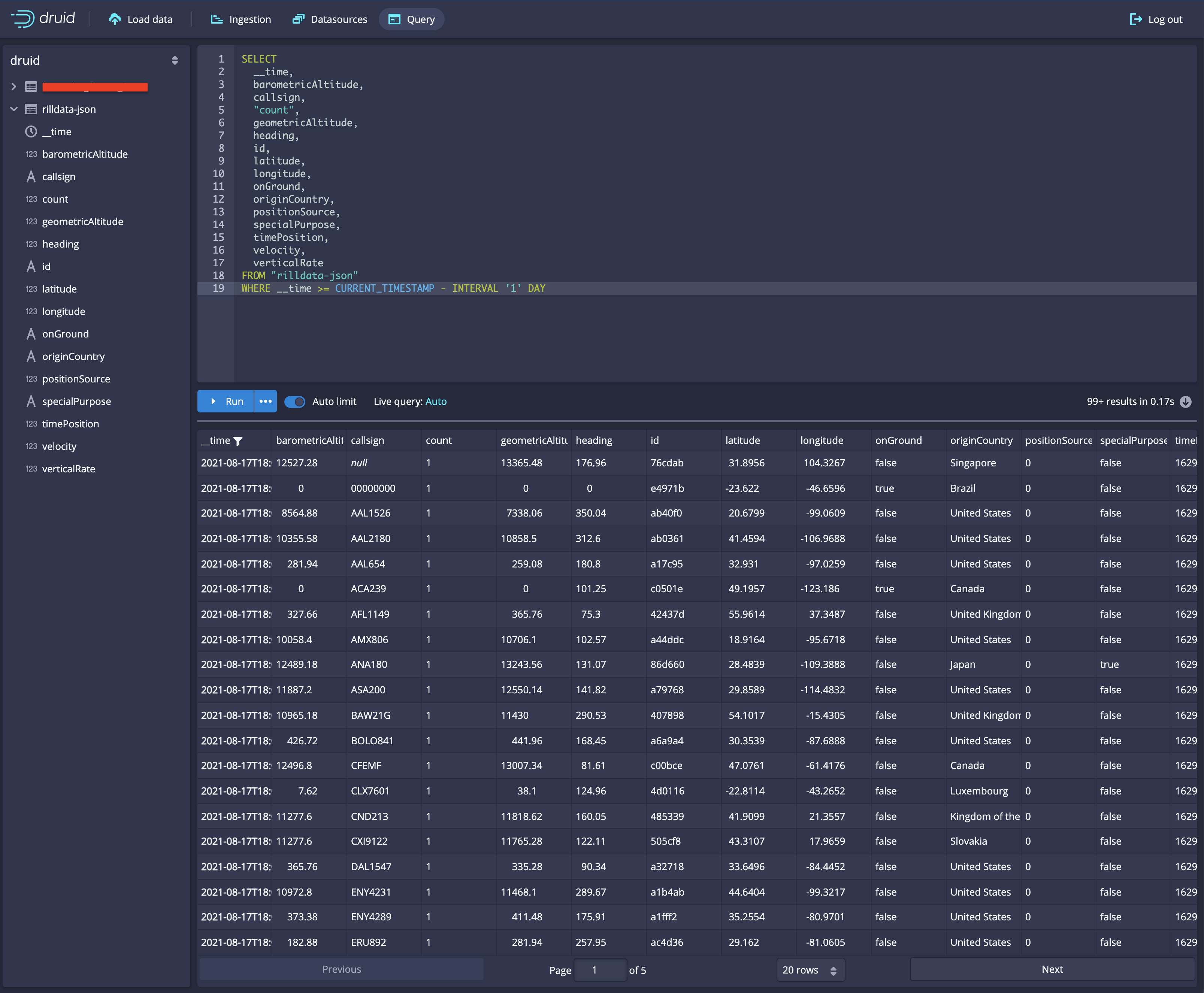
From here you can query your data using Druid SQL. Note that by default Smart query limit is set to 100. If you want more than 100 rows, turn this toggle off and use the limit SQL expression to specify your own limit. A description of Druid's SQL language can be found here: https://druid.apache.org/docs/0.21.0/querying/sql.html